業務事務処理で書類をスキャンしてPDFで保管してメールやワークフローで処理するというケース、結構ありますよね。
前職で社内の各種のドキュメント管理システムを構築、維持、運用してきた経験もあるので、日本語表記の文書をシステムで解析して分類する技術には非常に興味があり、AIや機械学習を応用することで、もっと精度よく、楽に分類、2次利用を支援する事が出来ないだろうかと調査してみました。
Pythonなら何でも出来そうな気がしていましたが、Google先生に相談を重ねてみると、学習済みの各国語の教師データもそろっている、オープンソースのOCRエンジンtesseract(テッセラクト)の存在を教えてもらいました。
オープンソースとなっていますが、由来はGoogle,HPのエンジニアが開発したとの情報もありますので、なんとなく安心感もあります・・・(;’∀’)
大雑把な流れとしては、
・tesseract(テッセラクト) をWindowsに導入
・環境変数を設定してPathにtesseractの導入先ディレクトリを通しておく
・Pythonでコードを書いて画像形式の文書データをOCRさせる
・テキストが取得できる
となります。
tesseract(テッセラクト)自体は画像形式ファイルから文字列情報を生成するエンジンですので、GUI等の装備はありません。コマンドラインからテキスト情報を得られるCUIベースで利用が可能なことが強みだとも言えます。RPAから呼び出して・・・なんてことも簡単に出来そうですから、わざわざ高価なOCRオプションを導入せずとも、tesseract+Python+RPAで多くの単調な事務仕事のロボット化が実現できそうだよなぁ・・と思ってしまうわけです。
では、作業記録です
- tesseractをインストール
https://github.com/UB-Mannheim/tesseract/wiki
インストーラを起動したら、セットアップ中のオプションで、日本語用のデータをダウンロード指定可能ですので、私はJapanese関連の4点を指定しておきました。
各国語の教師データはこちらから入手可能です
https://github.com/tesseract-ocr/tesseract/wiki/Data-Files
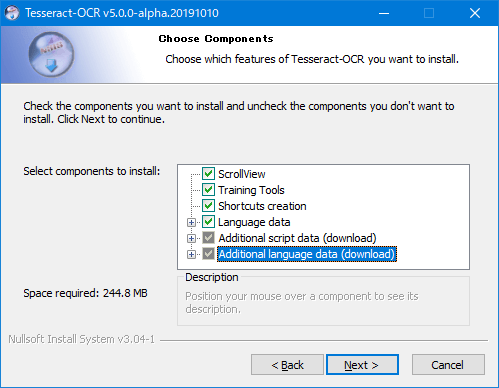


- 環境変数 PATH にtessaractのディレクトリを追加する
C:\Program Files\Tesseract-OCR
私の環境では上記を追加します。
- コマンドプロンプトから動作確認
テキスト情報を含んだ画像ファイルを適当なフォルダへ保管して、以下のコマンドでtxtファイルを生成してみます。
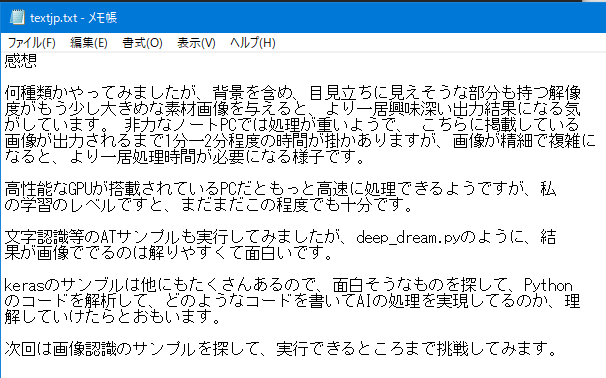
tesseract blog9.png textjp -l jpn
以下が素材とその結果です。完璧な結果ですが、紙面からスキャンした訳ではないので当然でしょうか・・・。

- PythonのOCRライブラリ pyocr の導入
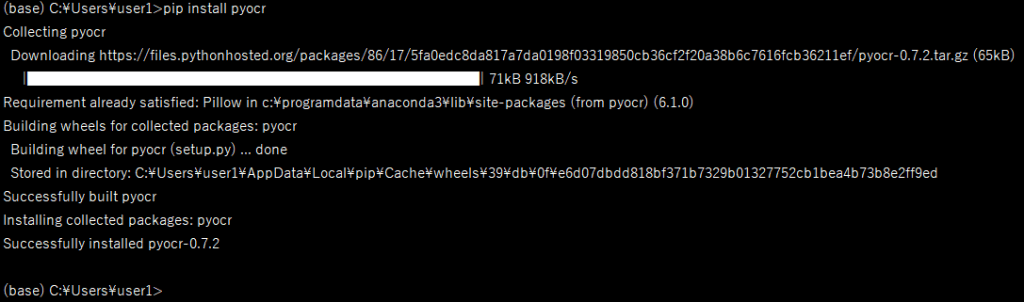
Anacondaプロンプトからpip でインストールします。
pip install pyocr
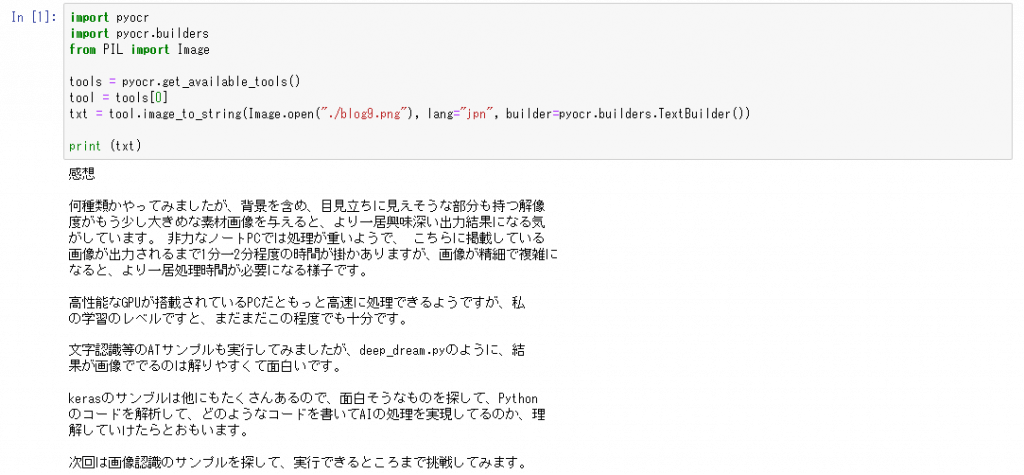
- Python(Jupyter Notebook)を使って実行
import pyocr
import pyocr.builders
from PIL import Image
tools = pyocr.get_available_tools()
tool = tools[0]
txt = tool.image_to_string(Image.open(“blog9.png”), lang=”jpn”, builder=pyocr.builders.TextBuilder())
print (txt)
※ blog9.png は JupyterNotebook のコードの実行ディレクトリに配置しておきます
感想
紙をスキャンして画像データにして、OCRの結果も確認してみましたが、機械学習技術をベースにしたOCRが故なのかどうかわかりませんが、以前より知っている複合機の追加機能のOCR処理より高速かつ精度が十分に満足のいく結果であると思いました。
tesseractのCUIベースでテキストを取り出せるUIは、様々はシステムと連携処理できる特徴でもあるので、応用範囲は広いだろうと思いました。
先月から今月にかけて、画像のクラスタリングのサンプルを実行したりしていましたが、より実用的な興味として、自然言語処理の基礎解析に興味が以降している関係もあって、ここんところは、日本語解析の準備作業みたいになってます。
クライアントさんに、紙⇒PDFとしたデータの2次利用のテーマがありますので、今後はPDFからテキスト情報を抽出するサンプルを探して、検証するところまで挑戦してみます。